Quickie: Alle *.csv-Dateien eines Verzeichnisses / Ordners mit Power Query einlesen
Um alle csv-Dateien eines Verzeichnisses einschließlich eventuell vorhandener Unterverzeichnisse einzulesen, gehen Sie prinzipiell genauso vor, wie bei „normalen” Excel-Files. Dieses Vorgehen ist hier im Blog ausführlich beschrieben. Darum an dieser Stelle nur ein Kurzdurchgang, weil sich nur sehr wenig ändert. Die hier beschriebene Übung basiert auf Daten des Deutschen Bundestages. Eine Datei mit einem Verzeichnis einschließlich mehrerer *.csv-Dateien (und anderer) können Sie hier herunterladen.
Natürlich werden Sie sich erst einmal merken müssen, in welchem Verzeichnis (Folder) die zu importieren Files enthalten sind. Eventuell vorhandene Sub Directories (Unterverzeichnisse) werden ohne Ihr Zutun automatisch mit eingelesen; soll nur die oberste Ebene ausgewählt werden, werden Sie diese im Abfrage-Editor filtern. Weiter get’s in jedem Fall so:
- Menü Daten bzw. Menüpunkt Power Query
- Neue Abfrage | Aus Datei | Aus Ordner
- Im Dialogfenster (Ordner) wählen Sie das entsprechende Verzeichnis über die Schaltfläche Durchsuchen… oder tragen Sie den Ordnerpfad per Hand in das Textfeld ein. Bestätigen Sie mit OK.
- Im folgenden Dialog werden alle oder zumindest die ersten Files des Directories zwecks Prüf-Möglichkeit angezeigt. Starten Sie den Import mit Klick auf Bearbeiten.
- Wenn in dem Verzeichnis nicht ausschließlich csv-Dateien enthalten sind, dann werden Sie die Extension entsprechend filtern.
- Sind auch Unterverzeichnisse eingelesen worden und sie möchten nur die oberste Ebene auswerten, dann filtern sie auch die Spalte Folder Path.
- In der Menüzeile wählen Sie das Register Spalte hinzufügen.
- Wählen Sie im Menüband denersten Punkt Benutzerdefinierte Spalte.
Im sich aufbauenden Dialog tragen Sie nun in exakt der hier angezeigten Schreibweise nach dem = diese Formel ein: csv.Document([Content]). Den Schlüsselbegriff Content, eingeschlossen in die eckigen Klammern, können Sie auch durch Doppelklick auf den entsprechenden Eintrag im rechten Bereich des Fensters übertragen.
Um den Editor etwas „schlanker” zu gestalten, ein Rechtsklick in die Überschrift der neu erstellten Spalte und im Kontextmenü dann Andere Spalten entfernen. Sie werden sehen, dass Sie keine der Spalten links der gerade erstellten brauchen. In der nun einzig verbliebenen Spalte ein Klick auf den „Doppelpfeil” ganz rechts und es zeigt sich solch ein Dialog:
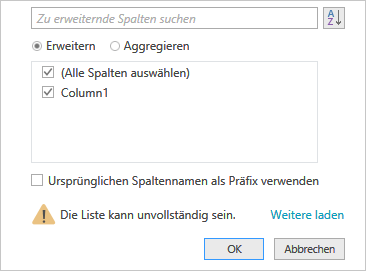
Auswahl: Welche Spalten sollen gezeigt werden?
Da jetzt nur noch eine Spalte existiert, können, nein müssen Sie (Alle Spalten auswählen) angehakt lassen. Wo Sie das Häkchen allerdings entfernen: Ursprünglichen Spaltennamen als Präfix verwenden, das soll nicht sein. Das Ergebnis wird Sie wahrscheinlich genau so überraschen wie mich beim ersten Mal. Und mir fiel nur ein Wort ein:

Frust!
Nicht weil nur die Namen und Vornamen dort drin stehen und keine Möglichkeit besteht, die Fraktion zuzuordnen. Das liegt an der Datebquelle als auch der Art des Imports und das ist OK und auch so gewollt. Nein, alle Umlaute und auch das „ß” werden als Fragezeichen in einer Raute dargestellt. Und wenn Sie nun denken, das sei das falsche Daten-Format, dann öffnen Sie doch probehalber einmal eine der csv-Files mit einem Doppelklick. Excel wird die Datei laden und alles wird korrekt dargestellt.
Na gut, beim ersten Versuch habe ich eine Datei in einen „vernünftigen” Editor geladen (Notepad++) und mir dort angesehen. Natürlich wurde hier auch alles so dargestellt, wie es sein sollte. Alle Umlaute OK. Mit einiger Experimentierfreude habe ich dann herausbekommen, dass ich die Datenquelle in ein anderes Codepage-Format wandeln kann. Gesagt, getan. Bei Kodierung ist ANSI angegeben; Konvertiere zu UTF‑8 angeklickt, gespeichert, die anderen csv-Dateien gleichermaßen umcodiert und im PQ-Editor die Aktualisieren-Schaltfläche gedrückt. Warum nicht gleich so…?
Nun ja, wenn ich im Vorwege die Codierung einer csv-Datei kenne, dann ist das eine Möglichkeit. Das kostet „nur” etwas Zeit. Und da Notepad++ sogar die Möglichkeit bietet, solche Vorgänge per Makrorecorder aufzuzeichnen und dann vereinfacht abzuspielen, ist das ein durchaus gangbarer Weg.
Bleibt dann nur noch als letzter Schritt, die beiden Namens-Bestandteile, die ja durch ein Semikolon getrennt sind, zu trennen und in zwei Spalten anzuordnen. Da gibt es im Register Start und Transformieren jeweils eine Schaltfläche Spalte teilen, womit Sie komfortabel zum gewünschten Ziel gelangen. Anschließend die Überschriften anzupassen, sollte Ihnen keine Schwierigkeiten bereiten.
Vielleicht interessiert Sie das Thema verstärkt … Dann schauen Sie doch einfach auch einmal hier im Blog zum Thema „Und täglich eine neue Liste” vorbei.
Hat Ihnen der Beitrag gefallen?
Erleichtert dieser Beitrag Ihre Arbeit?
Dann würde ich mich über einen Beitrag Ihrerseits z.B. 2,50 € freuen …